(L10n, I18n, língua, data, hora, timezone, condificação etc)
Localization ou L10n é forma que o mundo Unix tem de regionalizar uma distribuição, um programa, um documento etc para uma determinada localidade/região. Por exemplo, no Brasil seria interessante que os programas tivessem os seus menus ou manuais na língua brasileira (pt-br), a data de uma distribuição na mesmo formato. Quando isso acontece dizemos que houve um L10n. O L10n na verdade é um compactação do nome Localization, onde entre o "L" e o "n" existem 10 letras, ou seja, L10n. A tradução de Localization ao pé da letra seria Localização, no entando, o mais certo é traduzir como Regionalização.
A Internazionalization ou I18n é a forma que o mundo Unix tem de deixar uma distribuição, um programa, um documento etc internacional, ou seja, ele pode ser regionalizado para a maiora dos países, por exemplo, para o Brasil, USA, Itália etc de acordo com a vontade do usuário. O I18n na verdade é um compactação do nome Internazionalization, onde entre o "I" e o "n" existem 18 letras, ou seja, I18n.Qual a diferença entre Localization e Internazionalization? A Localization é o processo de adaptação de um software para uma região ou linguagem específica, adicionando componentes específicos e traduzindo texto que não foram incluido no projeto inicial. Já a Internazionalization é o processo de projetar ou desenvolver um software desde o inicio já adaptado para várias regiões e linguagens sem a necessidde de mudar a sua engenharização ou codificação. A Localization geralmente precisa mexer mais profundamente no software em questão e/ou adicionar pacotes extras ou atualizações para conseguir o objetivo. Já a Internazionalization prover uma maneira fácil de mudar a região, geralmente abertando um botão ou executando um comando a mais.
Um bom exemplo prático de Localization é de um software feito somente para ser vendido numa região (ex: USA). Só que surgiu a necessidade de vendê-lo para empresas brasileiras. Assim, haverá necessidade regionalizá-lo para o Brasil, ou seja, traduzir manuais e menus, mudar pesos, medidas, moeda, simbolos, audio, vídeo, data, hora, fuso horário, horário de verão, valores culurais e contexto social. Já um exemplo prático de Internazionalization é de um software feito desde o início para ser vendido mundialmente, onde para adaptá-lo à uma região, basta dar alguns cliques ou digitar alguns comandos.
O I18n prepara um software para ser internazinalizado/globalizado. Já o L10n prepara um software para ser regionalizado. Algo interessante é que apesar do I18n preparar um software para ser internazinalizado, ao fazê-lo, o I18n está fazendo várias regionalizações, ou seja, várias L10n.
(timezone)
Timezone, conhecido no Brasil como Fuso Horário, é a diferença em horas de uma região (ex: Brasil/Sao_Paulo) em relação ao meridiando de Greenwich. Para verificar o fuso horário que está configurado no sistema digite:
Time Zone do Sistema/Global
# vi /etc/timezone (provavelmente aparecerá algo como o da linha a seguir. Não mude esse arquivo diretamente, use o comando "dpkg-reconfigure tzdata" que será mostrado log a frente)
America/Sao_Paulo
Time Zone do Usuário/Individual
$ vi ~/.profile (provavelmente aparecerá algo como o da linha a seguir. Esse arquivo pode ser mudado diretamente)
TZ='America/Sao_Paulo'; export TZ
Data e Hora atual/local/regional
# date
Data e Hora atual do meridiando de Greenwich
# date -u | --utc | --universal
Date e Hora atual de acordo com a RFC-2822
# date -R | --rfc-2822 (mostra o fuso horário da região. Ex: aqui no Brasil geralmente é "-0300", ou seja, menos 3 horas em relação ao Greenwich)
Informações para o sistema do timezone atual
# ls -lh /etc/localtime (esse é um arquivo de dados que contém a "hora local/atual" calculado em cima do TimeZone atual do sistema operacional. Na verdade ele é um link simbólico ou um cópia de um dos arquivos que ficam em "/usr/share/zoneinfo/")
# zdump /etc/localtime (mostra a hora atual/local calculada em cima do TimeZone)
# zdump -v /etc/localtime (idem, só que mostra também os horários de verão antigo, atual e futuro, ou seja, o período de tempo em que o sistema operacional mudará a hora por causa do horário de verão)
# zdump /etc/localtime ; zdump /usr/share/zoneinfo/America/Sao_Paulo ; zdump /usr/share/zoneinfo/Brazil/East (perceba esses valores com o comando "zdump")
Diretório que contém todos timezone do mundo
# ls /usr/share/zoneinfo/
Verificado o horário de localidades diferentes - 1
# env TZ=America/Sao_Paulo date
# env TZ=America/Los_Angeles date
# env TZ=America/Bogota date
# env TZ=Africa/Ceuta date
# env TZ=Africa/Nairobi date
# env TZ=Asia/Tokyo date
Verificado o horário de localidades diferentes - 2
$ tzselect (entra num ambiente interativo para visualizar o timezone de outras regiões)
Mudar o timezone do Sistema/Global
# tzconfig (obsoleto, use o comando a seguir)
# dpkg-reconfigure tzdata (mostra um dialog interativo que muda o timezone para todos os usuários e é persistente a reinicializações. Ele muda o arquivo "/etc/timezone")
ou
# ln -s /usr/share/zoneinfo/America/Sao_Paulo /etc/localtime (obsoleto, use o comando a seguir)
Mudar o timezone do Usuário/Individual
$ vi ~/.profile (adicione a linha a seguir)
export TZ=America/Sao_Paulo (exporta a variável de ambiente "TZ" com o timezone correspondente)
Obs: ao mudar o timezone, não é mudado o horário do sistema, somente a referência em relação a meridiano de Greenwich. Assim, em um sistema podemos ter vários usuários de várias regiões diferentes, configurando para cada (~/.profile) um timezone compatível.
(localidade)
No GNU/Linux é muito fácil e intuitivo a parte de mudança de idioma, codificação, simbolos, modeda, pesos, medidas etc.
Habilitar um locale (idioma e codificação) disponível
# vi /etc/locale.gen (para utilizar um locale, se deve descomentá-lo nesse arquivo. Para realizar alguns testes logo adiante, descomente o pt_BR ISO-8859-1, "pt_BR.UTF-8 UTF-8", "fr_FR ISO-8859-1", "fr_FR.UTF-8 UTF-8"i, "es_ES ISO-8859-1" e "es_ES.UTF-8 UTF-8")
# locale-gen (reler o arquivo anterior halitando os locales que estão descomentados)
Mudando o idioma em tempo de execução
$ env LANG=pt_BR df (muda a saída do comando "df" para português_brasileiro)
$ env LANG=pt_BR.UTF-8 df (muda a saída do comando "df" para português_brasileiro, resolvendo alguns problemas de acentuação)
$ env LANG=fr_FR df (muda a saída do comando "df" para francês)
$ env LANG=fr_FR.UTF-8 df (muda a saída do comando "df" para francês, resolvendo alguns problemas de acentuação)
$ env LANG=es_ES df (muda a saída do comando "df" para espanhol)
$ env LANG=es_ES.UTF-8 df (muda a saída do comando "df" para espanhol, resolvendo alguns problemas de acentuação)
$ env LANG=en_US df (muda a saída do comando "df" para inglês)
$ env LANG=en_US.UTF-8 df (muda a saída do comando "df" para inglês, resolvendo alguns problemas de acentuação)
$ env LANG=C df (muda a saída do comando "df" para POSIX, sendo padrão o inglês)
$ env LANG=POSIX df (idem)
Obs1: a LANG=C é muito usada em scripts, pois ela é o padrão para aplicações, significando que as strings (caracteres) são mostrados da mesma maneira em que foram escritas, ou seja, sem regionalizar.
Obs2: existem vários tipos de codificação de caracteres como ASCII, EBCDIC e UTF. Esses tipos de codificação de caracteres nada mais são do que tabelas que ligam caracters (ex: a, b, c etc) a números em decimal (ex: 97, 98, 99 etc). Ao invés de decimal, poderia ser octal ou hexadecimal. Na área de computação, essas tabelas ligam caracters (ex: a, b, c etc) a números binários (ex: 1100001, 1100010, 1100011 etc). Com isso, podemos interagir com os computadores que só entendem binários (0 e 1), por exemplo, ao se digitar um texto, o computador sabe traduzir as teclas apertadas (que sao sinais digitais, ou seja, binários) em caracteres que são colocados no seu editor. Muito fácil, não?
Obs3: ASCII = ISO-8859-1. ASCII tem 7 ou 8 bits, ou seja, pode representar 128 ou 256 caracteres. Unicode = UTF. UTF-8 tem 8 bits = 256 caracteres. UTF-16 tem 16 bits = 65536 caracteres. UTF-8 tem 32 bits = 4294967296 caracteres. EBCDIC tem 8 bits. ASCII significa American Standard Code for Information Interchange. UTF significa Unicode Transformation Format. EBCDIC significa Extended Binary Coded Decimal Interchange Code. O EBCDIC foi usado nos mainframes antigos da IBM, pois precisavam de um número maior de caracteres do que a tabela ASCII de 7 bits poderia oferecer naquela época. O EBCDIC foi uma invenção da IBM. O ASCII está se tornando obsoleto, pois não consegue mais representar todos os caracteres existentes no mundo, por exemplo, a língua japonesa tem mais de dois mil caracteres. Devido a isso, está havendo uma transição gradual do ASCII para o Unicode. A ISO-8859-1 nada mais é do que a padronização da ISO para a tabela ASCII. A ISO-8859-1 representa os caracteres do West European (Latin-1), A ISO-8859-2 representa os caracteres do Central e East European (Latin-2), a ISO-8859-3 representa os caracteres do SouthEast European e miscellaneous (Latin-3). Já a ISO-8859-15 é equivalente a ISO-8859-1 e representa os caracteres do West European também, contudo, ele é para o Latin-9 (pouquíssimas diferenças entre ISO-8859-15 e a ISO-8859-1). A ISO-8859-15 é uma atualização da ISO8859-1 e veio para colocar alguns símbolos faltantes.
Obs4: a tendência mundial é substituir ASCII (ISO-8859 ou mais especificamente ISO-8859-1) pelo Unicode (UTF) devida a pequena quantidade de caracteres que o ASCII pode representar, 7 ou 8 bits. UTF-8 (Unicode Transformation Format 8-bit) é a condificação de caracteres (character encoding) de transição para o UTF-16 e UTF-32. Ele tem o intuito manter compatibilidade com o ASCII (American Standard Code for Information Interchange) durante essa transição. Por essa razão, ele tem se tornado um padrão dominante para arquivos, páginas web, e-mail e processadores de texto.
Verificando as informações de localidade do usuário atual
# locale (veja na figura a seguir a sua saída na tela)
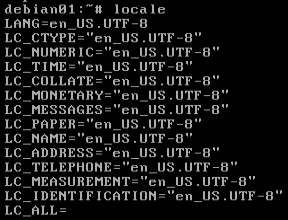
- LANG: muda o idioma, ou seja, ao mudar essa variável é mudada todas as LC_*;
- LC_CTYPE: classifica os caracteres e a conversão das caixas (baixa e alta);
- LC_NUMERIC: define o formato dos números não monetários;
- LC_TIME: formato da data e hora;
- LC_COLLATE: define a ordem alfabética;
- LC_MONETARY: formato monetário (da moeda);
- LC_MESSAGES: formato das mensagens do sistema;
- LC_PAPER: tamanho do papel;
- LC_NAME: formato do nome;
- LC_ADDRESS: formato do endereço e informações de localização;
- LC_TELEPHONE: formato do número de telefone;
- LC_MEASUREMENT: formato das unidades medidas (métricas);
- LC_IDENTIFICATION: metadados sobre a informação de localização;
- LC_ALL: muda o idioma, ou seja, ao mudar essa variável é mudada todas as LC_*;
# locale -av (idem, mas com detalhes)
Base de dados dos idiomas
$ ls /usr/share/i18n/
Mais informações
man locale
man 5 locale
man 7 locale
Existe um maneira em linha de comando de coverter um arquivo que está num tipo de codificação (ex: UTF-8) em outra (ex: UTF-16). O comando "iconv" é usado para isso, ou seja, muda o tipo de cotificação de caracter.
Listar o tipos de condificação disponíveis
$ iconv -l
$ recode -l
Convertendo - 1
$ echo "Teste Teste" > matrix.txt
$ file matrix.txt (verifica o tipo de arquivo. Nesse caso, aparecerá "ASCII text")
$ iconv -f ASCII -t UTF16 matrix.txt -o matrix.txt2 (converte de ASCII para UTF16)
$ iconv -f ASCII -t UTF16 < matrix.txt > matrix.txt2 (idem)
$ file matrix.txt* (verifica o tipo de arquivo novamente)
$ iconv --from-code=UTF-8 --to-code=Windows-1252 test.txt > test_win.txt (converte de UTF8 para Windows-1252. Esse Windows-1252 é muito usado em páginas PHP, Bancos de Dados e Arquivos. Então, sempre que tiver dificuldade com conversão de arquivos, veja se não é essa codificação que é necessária. Essa codificação é um dos tipo das ISO-8859)
$ iconv -f UTF-8 -t Windows-1252 test.txt > test_win.txt (idem)
Convertendo - 2
$ echo "Teste Teste" > matrix.txt
$ file matrix.txt (verifica o tipo de arquivo. Nesse caso, aparecerá "ASCII text")
$ recode ISO-8859-1..UTF-16 matrix.txt7 (converte de ASCII (iso-8859-1) para UTF16)
$ file matrix.txt* (verifica o tipo de arquivo novamente)
Obs: o comando "recode", por padrão, não preserva o arquivo original.
(layout/mapa)
Instalar os Mapas de Teclado (Debian)
# apt-get install console-data (Instalar os Mapas de Teclado)
Mudar o idioma do teclado (Debian)
# loadkeys br-abnt2 (define o idioma brasileiro abnt2 para o teclado)
Diretório dos idiomas do teclado (Debian)
# ls /usr/share/keymaps/i386/qwerty/
# ls /usr/share/keymaps/i386/qwerty/br-abnt2.kmap.gz (arquivo que contém o idioma brasileiro abnt2 para o teclado)
Mudar o idioma do teclado (ubuntu)
# xmodmap /usr/share/xmodmap/xmodmap.br (define o idioma brasileiro para o teclado)
Diretório dos idiomas do teclado (ubuntu)
# ls /usr/share/xmodmap/
# ls /usr/share/xmodmap/xmodmap.br (arquivo que contém o idioma brasileiro para o teclado)
Referências Bibliográgicas